Analyse de données
L'Analyse de Variance
Guide méthodologique complet L'Analyse de Variance (ANOVA) expliquée par le code De l'import du fichier Excel à la conclusion automatisée — chaque ligne du script Python décryptée, chaque test statistique illustré.…
Guide méthodologique complet
L'Analyse de Variance (ANOVA) expliquée par le code
De l'import du fichier Excel à la conclusion automatisée — chaque ligne du script Python décryptée, chaque test statistique illustré. L'objectif de cette méthode : Dans notre étude, nous avons testé 3 scénarios différents impliquant un agent d'Intelligence Artificielle (IA) chargé de commander des repas à la cantine. L'ANOVA est l'outil statistique qui permet de savoir si la perception des utilisateurs change réellement d'un scénario à l'autre, ou si les écarts de notes (sur l'échelle de 1 à 5) sont simplement dus au hasard des profils interrogés. Sommaire
- Chargement & recodage des données
- Analyse en Composantes Principales (ACP)
- Statistiques descriptives
- Test de Levene (homogénéité)
- Table ANOVA & test de Welch
- Tailles d'effet (η² et ω²)
- Comparaisons post-hoc (Tukey)
- Double boucle & synthèse finale
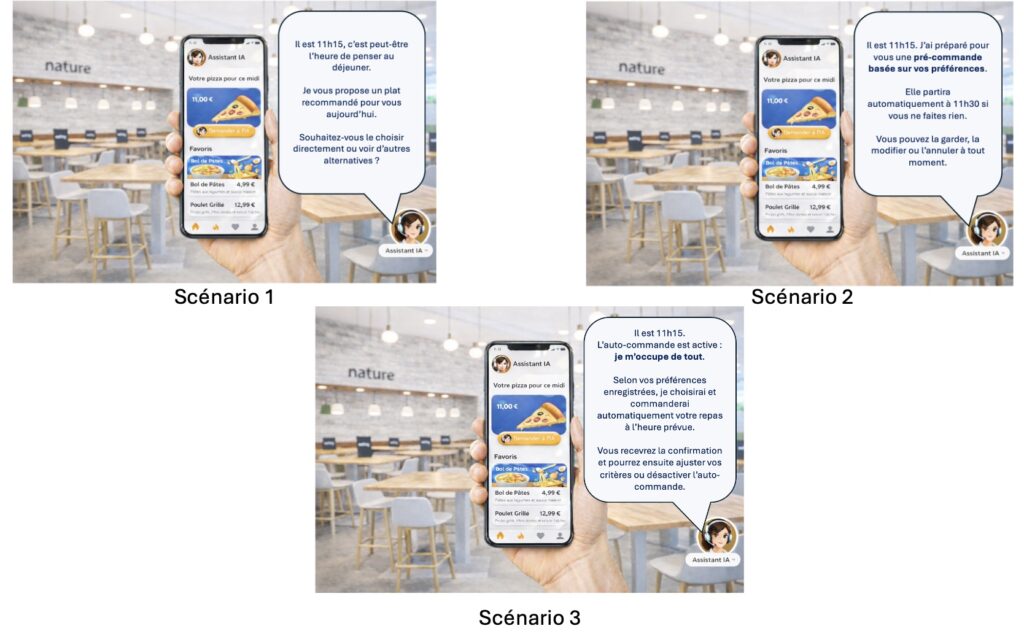 Figure 1 — Les trois stimuli (Scénarios 1, 2 et 3) présentés aux participants.
Figure 1 — Les trois stimuli (Scénarios 1, 2 et 3) présentés aux participants.
🔍 Les 4 dimensions mesurées (variables dépendantes)
Chaque participant évalue l'agent sur ces 4 construits, mesurés via plusieurs items sur une échelle de Likert (1 à 5) :
- Alignement (5 items) — L'agent agit-il dans mon intérêt ou celui du restaurant ?
- Compétence (4 items) — L'agent fait-il de bonnes suggestions de repas ?
- Contrôle (5 items, dont 1 inversé) — Est-ce que je garde la main sur la commande ?
- Intention d'usage (4 items) — Suis-je prêt(e) à utiliser ce mode à l'avenir ?
La variable indépendante (facteur) est le numéro de scénario, stocké dans la colonne GROUPE (valeurs 1, 2 ou 3).
Vue d'ensemble du pipeline
Chaque nœud correspond à une section précise du code Python. ImportExcel → Pandas › RecodageItems inversés › ACPScore global › DescriptifsMoy. / É.-T. › LeveneHomogénéité › ANOVA/ Welch › Effetη² & ω² › TukeyPost-hoc
Chargement et préparation des données
Le socle de toute analyse : importer, filtrer et recoder. Étape 0A · Importation Charger le fichier Excel et sélectionner les groupes Le script lit le fichier RC_AGENT.xlsx (feuille BASE), puis ne conserve que les lignes où GROUPE vaut 1, 2 ou 3 — ce qui exclut d'éventuels pré-tests ou données incomplètes. chargement.py [code] import pandas as pd import numpy as np
file_path = '/content/RC_AGENT.xlsx'
df = pd.read_excel(file_path, sheet_name='BASE')
# Filtrage : on ne garde que les 3 groupes expérimentaux
df_analysis = df[df['GROUPE'].isin([1, 2, 3])].copy()
[/code] Étape 0B · Recodage d'item inversé Retourner les échelles qui mesurent « à l'envers » L'item CTRL3R_S1 est formulé de façon négative (ex : « J'ai le sentiment de ne PAS avoir le contrôle »). Un score élevé (5/5) y signifie en réalité un faible contrôle perçu. Le code inverse donc l'échelle : 1↔5, 2↔4, 3 reste 3. Après recodage, un score élevé signifie toujours « plus de contrôle », comme pour les autres items du construit. recodage.py [code] # Inversion de l'échelle : 1↔5, 2↔4, 3=3 mapping_inverse = {1: 5, 2: 4, 3: 3, 4: 2, 5: 1} df_analysis['CTRL3R_S1'] = df_analysis['CTRL3R_S1'].map(mapping_inverse) [/code] 💡 C'est comme un thermomètre qui afficherait le froid au lieu de la chaleur : on retourne la graduation pour que toutes les mesures « montent » dans le même sens. Étape 0C · Définition des construits Associer chaque item à son concept théorique Le dictionnaire Python concepts regroupe les colonnes du questionnaire par dimension. Ce mapping sera utilisé à l'étape suivante (ACP) pour fabriquer un score unique par construit.
| Construit | Items du questionnaire | Nb |
|---|---|---|
| Alignement | ALIGN1_S1 … ALIGN5_S1 | 5 |
| Compétence | COMP1_S1 … COMP4_S1 | 4 |
| Contrôle | CTRL1_S1, CTRL2_S1, CTRL3R_S1, CTRL4_S1, CTRL5_S1 | 5 |
| Intention | INT1_S1 … INT4_S1 | 4 |
| Le dictionnaire item_labels fournit en parallèle un libellé lisible pour chaque code (ex : COMP2_S1 → « Fait de bonnes suggestions de repas »). Ces libellés apparaîtront dans les sorties console et les graphiques. |
Étape préliminaire — l'ACP
Résumer plusieurs questions en un score unique et robuste. ACP · Score global par construit Pourquoi ne pas simplement faire la moyenne des items ? On pourrait calculer la moyenne brute des 5 items d'Alignement. Mais l'Analyse en Composantes Principales (ACP) fait mieux : elle attribue un poids différent à chaque item selon sa contribution réelle à la dimension commune. Un item qui « colle » parfaitement au concept pèsera plus lourd qu'un item un peu périphérique. Le résultat est un score standardisé (centré-réduit) par participant, plus fiable statistiquement qu'une simple moyenne. Cliquez ici pour en savoir plus Le code enchaîne trois opérations pour chaque construit : acp.py [code] from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler
pca_df = pd.DataFrame({'GROUPE': df_analysis['GROUPE']})
for name, items in concepts.items():
# 1. Standardisation : moyenne → 0, écart-type → 1
scaler = StandardScaler()
# 2. Extraction de la 1ère composante principale
pca = PCA(n_components=1)
# 3. Projection : score unique par participant
pca_df[name] = pca.fit_transform(
scaler.fit_transform(
df_analysis[items].fillna(df_analysis[items].mean())
)
).flatten()
[/code] Détail des 3 opérations internes : 1. StandardScaler() — Chaque item est centré (moyenne ramenée à 0) et réduit (écart-type ramené à 1). Cela empêche un item dont les notes sont naturellement plus élevées ou plus dispersées de dominer le score final. 2. PCA(n_components=1) — On ne retient que la première composante, c'est-à-dire la direction de variance commune maximale entre les items. L'ACP trouve la combinaison linéaire qui explique le plus de variabilité : plus un item « va dans le même sens » que les autres, plus son poids (loading) sera élevé. 3. fillna(mean()) — Si un participant n'a pas répondu à une question, sa valeur manquante est remplacée par la moyenne de cet item pour ne pas perdre l'ensemble de ses données. 💡 Imaginez mesurer la « sportivité » d'un élève : plutôt que la moyenne simple de course, saut et natation, l'ACP donnera plus de poids à l'épreuve qui différencie le mieux les sportifs des non-sportifs. Résultat : Pour chaque participant, on dispose d'un score unique par construit (Alignement, Compétence, Contrôle, Intention). C'est ce score, issu de l'ACP, qui entre dans l'ANOVA — pas les items individuels. Le code exécute ensuite l'ANOVA item par item en complément (« Étape B ») pour identifier les questions spécifiques qui diffèrent.
Les 5 étapes de l'ANOVA
Chaque étape est exécutée automatiquement par la fonction run_full_analysis() pour chaque variable testée. Étape 1 · Statistiques descriptives Observer les moyennes et la dispersion avant tout test Premier réflexe du chercheur : regarder les chiffres bruts. Le code calcule la moyenne , l'écart-type , la variance et l'effectif de chaque groupe, puis identifie automatiquement quel scénario obtient la meilleure et la plus faible note. descriptifs.py [code] # Tableau récapitulatif par groupe desc = data.groupby('GROUPE')[target].agg( ['mean', 'std', 'count', 'var'] ).round(3)
# Identification automatique du meilleur / pire scénario
max_g = desc['mean'].idxmax()
min_g = desc['mean'].idxmin()
[/code] La méthode .agg() applique quatre fonctions d'agrégation à chaque groupe en un seul appel. Le code repère ensuite le meilleur et le pire scénario pour générer une phrase d'interprétation automatique. Mais attention : un écart de moyennes ne prouve rien à lui seul. Si le Scénario 1 obtient 3,9 et le Scénario 3 obtient 3,6, cette différence de 0,3 point pourrait n'être que du bruit statistique. Les étapes suivantes vont le vérifier. 💡 C'est comme comparer la température de deux villes un jour donné : 22 °C vs 24 °C. Avant de conclure qu'une ville est « plus chaude », il faudrait vérifier que cet écart se reproduit jour après jour. Étape 2 · Test de Levene Les avis sont-ils aussi dispersés d'un groupe à l'autre ? L'ANOVA classique repose sur une hypothèse technique : les trois groupes doivent avoir des variances à peu près égales. Le test de Levene vérifie cette condition. S'il la rejette, le résultat de l'ANOVA classique pourrait être faussé. levene.py [code] from scipy import stats
# Séparation des scores par groupe
g1 = data[data['GROUPE']==1][target]
g2 = data[data['GROUPE']==2][target]
g3 = data[data['GROUPE']==3][target]
# Test d'homogénéité des variances
levene_stat, levene_p = stats.levene(g1, g2, g3)
[/code]
La fonction stats.levene() de SciPy compare la déviation médiane des observations dans chaque groupe et renvoie une statistique F accompagnée de sa p-value :
p > 0,05 → Feu vert
Les variances sont homogènes. L'ANOVA classique est fiable.
p < 0,05 → Alerte
Un groupe est plus dispersé. Le code bascule vers le test de Welch (étape 3b).
💡 On compare les notes d'un examen entre 3 classes. Dans la classe A, tout le monde a entre 12 et 14 ; dans la classe C, les notes vont de 4 à 20. Comparer leurs moyennes serait trompeur : Levene détecte ce déséquilibre.
Étape 3A · Table ANOVA classique
Le moment de vérité — la p-value
L'ANOVA décompose la variation totale des scores en deux sources :
Variation inter-groupes (SSbetween) — la part de variation expliquée par le changement de scénario. Plus les moyennes des 3 groupes divergent, plus cette valeur est grande.
Variation intra-groupe (SSwithin) — la part « résiduelle » due aux différences individuelles. C'est le bruit naturel.
F = MSinter ÷ MSintra = (SSinter / dfinter) ÷ (SSintra / dfintra)
Plus F est grand, plus le signal (effet du scénario) domine le bruit (variabilité individuelle).
anova_classique.py
[code]
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# Modèle linéaire : score expliqué par le facteur GROUPE
model = ols(f"{target} ~ C(GROUPE)", data=data).fit()
anova_tab = anova_lm(model, typ=2)
# Extraction des composantes de la table
ss_bet = anova_tab.loc['C(GROUPE)', 'sum_sq'] # SS inter-groupes
ss_err = anova_tab.loc['Residual', 'sum_sq'] # SS intra-groupe
df_bet = anova_tab.loc['C(GROUPE)', 'df'] # ddl inter (k-1 = 2)
df_err = anova_tab.loc['Residual', 'df'] # ddl intra (N-k)
ms_bet = ss_bet / df_bet # Moyenne des carrés inter
ms_err = ss_err / df_err # Moyenne des carrés intra
f_stat = anova_tab.loc['C(GROUPE)', 'F']
p_val = anova_tab.loc['C(GROUPE)', 'PR(>F)']
[/code] La syntaxe C(GROUPE) indique à Python de traiter GROUPE comme une variable catégorielle : les valeurs 1, 2, 3 sont des étiquettes, pas des grandeurs numériques. Le paramètre typ=2 demande une ANOVA de type II — avec un seul facteur, les types I, II et III donnent les mêmes résultats. La table produite ressemble à ce qu'afficherait SPSS :
| Source | SS | df | MS | F | Sig. |
|---|---|---|---|---|---|
| Inter-groupes | SS bet | 2 | MS bet | F | p |
| Intra-groupe (Résiduel) | SS err | N − 3 | MS err | — | — |
| p < 0,05 → Effet significatif | |||||
| Moins de 5 % de chance que les écarts soient dus au hasard. | |||||
| p > 0,05 → Pas d'effet | |||||
| Les 3 scénarios génèrent la même perception. | |||||
| Étape 3B · Test de Welch (alternative robuste) | |||||
| Quand les variances ne sont pas homogènes | |||||
| Si Levene a déclenché une alerte (p < 0,05), le code bascule sur le test de Welch. Ce test pondère chaque groupe par l'inverse de sa variance : les groupes consensuels pèsent davantage, corrigeant le biais. | |||||
| welch.py | |||||
| [code] |
def welch_anova_test(data, target, group_col='GROUPE'):
k = data[group_col].nunique() # Nombre de groupes (3)
n = data.groupby(group_col)[target].count()
means = data.groupby(group_col)[target].mean()
vars_ = data.groupby(group_col)[target].var(ddof=1)
# Poids = effectif / variance → groupes consensuels pèsent plus
weights = n / vars_
sum_weights = weights.sum()
grand_mean_welch = (weights * means).sum() / sum_weights
# Statistique F de Welch
num = (weights * (means - grand_mean_welch)**2).sum() / (k - 1)
lam = ((1 - weights / sum_weights)**2 / (n - 1)).sum()
den = 1 + (2 * (k - 2) / (k**2 - 1)) * lam
f_welch = num / den
df1 = k - 1
# Degrés de liberté ajustés (souvent non entiers)
df2 = (k**2 - 1) / (3 * lam)
p_val = stats.f.sf(f_welch, df1, df2)
return f_welch, p_val
[/code] Points clés : — weights = n / vars_ : poids élevé pour les groupes homogènes, faible pour les groupes très dispersés. — grand_mean_welch : grande moyenne recalculée avec ces pondérations. — df2 : degrés de liberté ajustés par Welch-Satterthwaite, généralement non entiers (ex : 45,7), rendant le test plus conservateur. ⚠️ Post-hoc : le code prévient que lorsque Welch est utilisé, le test de Tukey (variances égales) n'est qu'indicatif. Le test de Games-Howell serait théoriquement préférable. Étape 4 · Tailles d'effet Significatif ne veut pas dire « important » Une p-value < 0,05 certifie l'existence d'un effet mais n'en mesure pas la force. Avec un très grand échantillon, même un écart infime devient significatif. Les tailles d'effet quantifient la puissance pratique. effet.py [code] def calculate_eta_omega(ss_bet, ss_err, df_bet, ms_err): ss_tot = ss_bet + ss_err
# η² — proportion brute de variance expliquée
eta2 = ss_bet / ss_tot
# ω² — estimation corrigée (moins biaisée)
omega2 = (ss_bet - (df_bet * ms_err)) / (ss_tot + ms_err)
return eta2, omega2
[/code]
η² = SSinter ÷ SStotal
Part de la variance totale expliquée par le facteur scénario.
η² (Eta-carré) est intuitif mais surestime l'effet. ω² (Omega-carré) corrige ce biais en retirant la part de hasard attendue (df_bet × ms_err). Si ω² tombe sous zéro, max(0, omega2) le force à 0.
η² < 0,06
Effet faible
0,06 ≤ η² < 0,14
Effet modéré
η² ≥ 0,14
Effet fort
Lecture concrète : Si η² = 0,08, cela signifie que 8 % des différences de perception entre participants s'expliquent par le scénario. Les 92 % restants proviennent d'autres facteurs (habitudes, âge, humeur…).
Étape 5 · Comparaisons post-hoc (Tukey HSD)
Quel scénario bat quel scénario ?
L'ANOVA dit « au moins un groupe diffère ». Le test de Tukey HSD compare chaque paire en contrôlant le risque d'erreurs multiples. Avec 3 groupes : 1 vs 2 , 1 vs 3 , 2 vs 3.
posthoc.py
[code]
from statsmodels.stats.multicomp import pairwise_tukeyhsd
# Uniquement si l'ANOVA (ou Welch) est significative
if reported_p < 0.05:
tukey = pairwise_tukeyhsd(data[target], data['GROUPE'])
print(tukey)
else:
print("Non nécessaire.")
[/code] Lecture de la sortie :
| Colonne | Signification |
|---|---|
group1 / group2 | Les deux scénarios comparés |
meandiff | Différence des moyennes (group2 − group1) |
p-adj | p-value ajustée pour comparaisons multiples |
lower / upper | Intervalle de confiance à 95 % |
reject | True = significatif ; False = non |
| Lecture : Si « 1 vs 3 » affiche reject = True, la perception diffère entre ces scénarios. meandiff positif = Scénario 3 mieux noté ; négatif = Scénario 1. | |
| Logique conditionnelle : Tukey n'est lancé que si p < 0,05 globalement. Sinon, le code affiche « Non nécessaire » pour éviter les faux positifs. |
La double boucle d'exécution
Le pipeline complet est appliqué deux fois, à deux niveaux de granularité. Architecture du script Étape A (globale) puis Étape B (détaillée) La fonction run_full_analysis() encapsule les 5 étapes. Le script l'appelle dans deux boucles : Étape A — Scores ACP (4 analyses) : appliquée aux 4 scores globaux. « Le scénario influence-t-il la perception globale de chaque dimension ? » Étape B — Items individuels (18 analyses) : appliquée aux 18 items bruts. « Sur quelle question précise le scénario fait-il bouger les réponses ? » L'Alignement global peut sembler stable, mais « L'agent serait honnête sur les limites des plats » pourrait diverger. execution.py [code] all_results = []
# ── ÉTAPE A : 4 construits globaux (scores ACP) ──
for name, items in concepts.items():
res = run_full_analysis(pca_df, name, f"Concept Global : {name}")
all_results.append(res)
# ── ÉTAPE B : 18 items individuels ──
for code, label in item_labels.items():
res = run_full_analysis(df_analysis, code, label)
all_results.append(res)
[/code] Chaque appel renvoie un dictionnaire (F, p, η², ω², test utilisé, Levene p), collecté dans all_results pour le tableau de synthèse.
Synthèse finale automatisée
Un tableau récapitulatif et un verdict en langage clair. Tableau de synthèse Tous les résultats en un coup d'œil synthese.py [code] summary_final = pd.DataFrame(all_results)
print(summary_final[[
'Variable', # Construit ou item
'Test_Appliqué', # "ANOVA" ou "Welch"
'F', # Statistique F
'p', # p-value
'Eta2', # Taille d'effet η²
'Omega2', # Taille d'effet ω²
'Levene_p' # p du test de Levene
]].to_string(index=False))
[/code] Ce tableau permet d'identifier d'un seul regard quelles variables ont un p < 0,05, quel test a été retenu, et la magnitude de chaque effet. Verdict automatique Conclusion en langage naturel conclusion.py [code] sig_found = summary_final[summary_final['p'] < 0.05]
if sig_found.empty:
print("Stabilité confirmée : même perception.")
else:
print(f"Divergence : {len(sig_found)} variable(s) significative(s).")
[/code]
Aucune variable significative
« Stabilité confirmée » — l'agent IA est perçu de la même manière quel que soit le scénario.
Au moins une variable significative
« Divergence détectée » — le scénario a modifié l'opinion. Les tests post-hoc identifient lesquels.
Bonus · Visualisations
Boxplots superposés d'un nuage de points
Pour chaque variable, un boxplot (médiane, quartiles, extrêmes) combiné à un swarmplot (chaque point = un participant) permet de voir la tendance centrale, la dispersion et la distribution réelle des réponses.
graphiques.py
[code]
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(7, 4))
sns.boxplot(x='GROUPE', y=target, data=data,
hue='GROUPE', palette='Set2', legend=False)
sns.swarmplot(x='GROUPE', y=target, data=data,
color=".25", alpha=0.5, size=4)
plt.title(f"Répartition : {label}")
plt.show()
[/code] 💡 Le boxplot montre la « forêt » (tendance générale), le swarmplot les « arbres » (chaque individu). Si les boîtes se chevauchent largement, l'ANOVA ne trouvera probablement rien de significatif.
Code Python complet
Le script intégral, prêt à exécuter dans Google Colab ou Jupyter Notebook. analyse_anova_complete.py [code] import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt import warnings from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler import statsmodels.api as sm from statsmodels.formula.api import ols from statsmodels.stats.anova import anova_lm from statsmodels.stats.multicomp import pairwise_tukeyhsd from scipy import stats
# 1. CONFIGURATION ET NETTOYAGE
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.simplefilter(action='ignore', category=UserWarning)
pd.options.mode.chained_assignment = None
# 2. CHARGEMENT ET RECODAGE
file_path = '/content/RC_AGENT.xlsx'
df = pd.read_excel(file_path, sheet_name='BASE')
df_analysis = df[df['GROUPE'].isin([1, 2, 3])].copy()
mapping_inverse = {1: 5, 2: 4, 3: 3, 4: 2, 5: 1}
df_analysis['CTRL3R_S1'] = df_analysis['CTRL3R_S1'].map(mapping_inverse)
item_labels = {
'ALIGN1_S1': "Agit dans mon meilleur intérêt",
'ALIGN2_S1': "Privilégiera mes intérêts vs restaurant",
'ALIGN3_S1': "Ne poussera pas à un choix avantageux resto",
'ALIGN4_S1': "Serait honnête sur les limites des plats",
'ALIGN5_S1': "S'assurera que la commande me convient",
'COMP1_S1': "Comprend mes préférences alimentaires",
'COMP2_S1': "Fait de bonnes suggestions de repas",
'COMP3_S1': "Est fiable pour gérer la commande",
'COMP4_S1': "Est compétent pour choisir un repas",
'CTRL1_S1': "Sentiment de garder le contrôle (préférences)",
'CTRL2_S1': "Contrôle via ajustement des préférences",
'CTRL3R_S1': "Perception de contrôle personnel (Inversé)",
'CTRL4_S1': "Facilité à refuser/annuler",
'CTRL5_S1': "Décision d'activer dépend de moi",
'INT1_S1': "Prévoit de laisser l'agent agir en mon nom",
'INT2_S1': "Compte laisser l'agent gérer la commande",
'INT3_S1': "Prêt à activer mode sans validation",
'INT4_S1': "Continuerait à utiliser ce mode à l'avenir"
}
concepts = {
'Alignement': ['ALIGN1_S1','ALIGN2_S1','ALIGN3_S1','ALIGN4_S1','ALIGN5_S1'],
'Compétence': ['COMP1_S1','COMP2_S1','COMP3_S1','COMP4_S1'],
'Contrôle': ['CTRL1_S1','CTRL2_S1','CTRL3R_S1','CTRL4_S1','CTRL5_S1'],
'Intention': ['INT1_S1','INT2_S1','INT3_S1','INT4_S1']
}
def calculate_eta_omega(ss_bet, ss_err, df_bet, ms_err):
ss_tot = ss_bet + ss_err
eta2 = ss_bet / ss_tot
omega2 = (ss_bet - (df_bet * ms_err)) / (ss_tot + ms_err)
return eta2, omega2
def welch_anova_test(data, target, group_col='GROUPE'):
k = data[group_col].nunique()
n = data.groupby(group_col)[target].count()
means = data.groupby(group_col)[target].mean()
vars_ = data.groupby(group_col)[target].var(ddof=1)
weights = n / vars_
sum_weights = weights.sum()
grand_mean_welch = (weights * means).sum() / sum_weights
num = (weights * (means - grand_mean_welch)**2).sum() / (k - 1)
lam = ((1 - weights / sum_weights)**2 / (n - 1)).sum()
den = 1 + (2 * (k - 2) / (k**2 - 1)) * lam
f_welch = num / den
df1 = k - 1
df2 = (k**2 - 1) / (3 * lam)
p_val = stats.f.sf(f_welch, df1, df2)
return f_welch, p_val
def run_full_analysis(data, target, label):
print(f"\n{'#'*70}\nANALYSE : {label}\n{'#'*70}")
desc = data.groupby('GROUPE')[target].agg(['mean','std','count','var']).round(3)
print("\n[1] DESCRIPTIFS :")
print(desc)
max_g = desc['mean'].idxmax()
min_g = desc['mean'].idxmin()
print(f"\n💡 Scénario {max_g} = meilleure moyenne ({desc.loc[max_g,'mean']}), "
f"Scénario {min_g} = plus faible ({desc.loc[min_g,'mean']}).")
g1 = data[data['GROUPE']==1][target]
g2 = data[data['GROUPE']==2][target]
g3 = data[data['GROUPE']==3][target]
levene_stat, levene_p = stats.levene(g1, g2, g3)
print(f"\n[2] LEVENE : F={levene_stat:.3f}, p={levene_p:.4f}")
if levene_p > 0.05:
print("→ Variances homogènes. ANOVA classique OK.")
else:
print("→ Variances hétérogènes. Bascule vers Welch.")
model = ols(f"{target} ~ C(GROUPE)", data=data).fit()
anova_tab = anova_lm(model, typ=2)
ss_bet = anova_tab.loc['C(GROUPE)','sum_sq']
ss_err = anova_tab.loc['Residual','sum_sq']
df_bet = anova_tab.loc['C(GROUPE)','df']
df_err = anova_tab.loc['Residual','df']
ms_bet = ss_bet / df_bet
ms_err = ss_err / df_err
f_stat = anova_tab.loc['C(GROUPE)','F']
p_val = anova_tab.loc['C(GROUPE)','PR(>F)']
eta2, omega2 = calculate_eta_omega(ss_bet, ss_err, df_bet, ms_err)
print(f"\n[3a] TABLE ANOVA :")
print(f"{'Source':<12} | {'SS':<10} | {'df':<4} | {'MS':<10} | {'F':<8} | {'Sig.':<8}")
print(f"{'Inter-Group':<12} | {ss_bet:<10.3f} | {df_bet:<4.0f} | {ms_bet:<10.3f} | {f_stat:<8.3f} | {p_val:<8.4f}")
print(f"{'Intra-Group':<12} | {ss_err:<10.3f} | {df_err:<4.0f} | {ms_err:<10.3f} |")
if levene_p < 0.05:
print("\n[3b] ⚠️ TEST DE WELCH :")
f_welch, p_welch = welch_anova_test(data, target, 'GROUPE')
print(f"F(Welch)={f_welch:.3f}, p={p_welch:.4f}")
reported_f, reported_p, test_used = f_welch, p_welch, "Welch"
else:
reported_f, reported_p, test_used = f_stat, p_val, "ANOVA"
if reported_p < 0.05:
print(f"\n💡 [{test_used}] p < 0,05 → Effet significatif.")
else:
print(f"\n💡 [{test_used}] p > 0,05 → Pas d'effet.")
print(f"\n[4] η²={eta2:.4f}, ω²={max(0,omega2):.4f}")
mag = "faible" if eta2<0.06 else "modérée" if eta2<0.14 else "forte"
print(f"→ Effet {mag} ({eta2*100:.1f}% de variance expliquée).")
if reported_p < 0.05:
print("\n[5] TUKEY HSD :")
if test_used == "Welch":
print("(Games-Howell serait préférable)")
tukey = pairwise_tukeyhsd(data[target], data['GROUPE'])
print(tukey)
else:
print("\n[5] Post-hoc non nécessaire.")
plt.figure(figsize=(7, 4))
sns.boxplot(x='GROUPE', y=target, data=data,
hue='GROUPE', palette='Set2', legend=False)
sns.swarmplot(x='GROUPE', y=target, data=data,
color=".25", alpha=0.5, size=4)
plt.title(f"Répartition : {label}")
plt.xlabel("Scénario"); plt.ylabel("Score")
plt.show()
return {'Variable': label, 'Test_Appliqué': test_used,
'F': round(reported_f,3), 'p': round(reported_p,4),
'Eta2': round(eta2,4), 'Omega2': round(max(0,omega2),4),
'Levene_p': round(levene_p,4)}
all_results = []
print("=" * 70)
print("ÉTAPE A : CONCEPTS GLOBAUX (ACP)")
print("=" * 70)
pca_df = pd.DataFrame({'GROUPE': df_analysis['GROUPE']})
for name, items in concepts.items():
scaler = StandardScaler()
pca = PCA(n_components=1)
pca_df[name] = pca.fit_transform(
scaler.fit_transform(
df_analysis[items].fillna(df_analysis[items].mean())
)).flatten()
all_results.append(run_full_analysis(pca_df, name, f"Global : {name}"))
print("\n\n" + "=" * 70)
print("ÉTAPE B : ITEMS INDIVIDUELS")
print("=" * 70)
for code, label in item_labels.items():
all_results.append(run_full_analysis(df_analysis, code, label))
summary_final = pd.DataFrame(all_results)
print("\n" + "=" * 100)
print("TABLEAU SYNTHÉTIQUE FINAL")
print("=" * 100)
print(summary_final[['Variable','Test_Appliqué','F','p',
'Eta2','Omega2','Levene_p']].to_string(index=False))
sig = summary_final[summary_final['p'] < 0.05]
if sig.empty:
print("\n→ Stabilité : aucune différence significative.")
else:
print(f"\n→ {len(sig)} variable(s) significative(s). Voir tests post-hoc.")
[/code] Guide méthodologique — Étude Agent IA & Commande de repas — ANOVA & Python